Using Ghidra on MSVC WIN32 binaries
To develop binaries for Windows it is very common to use Visual Studio along with the MSVC compiler and linker. Visual Studio does a few things under the hood to convert a small C or C++ program into a secure and optimized binary. To understand this we will look into some of these things as well as WIN32 API specifics you might come across and how to detect them.
Calling conventions
When calling a method the arguments need to be passed to it. You can read more details about this in the Wikipedia X86 calling conventions article, but the most common ones to find in a binary are:
cdecl
This is commonly used by static class methods (i.e. anything that does not touch the state of the instance). It i also used by most C methods as well as methods outside of any class.
stdcall
The stdcall is used in most places on the Windows API, especially on methods imported from DLLs. It can be hard to distinguish from thiscall, not only for you but also for Ghidra. You see ECX an Stack as input and EAX as output.
thiscall
As the name suggests its being primarly used on classes and for most of the cases you can assume identical behaviour like stdcall. Ghidra takes care for type management for you of the this pointer, which is really nice. The this pointer is in ECX, the arguments on the Stack and EAX is the output.
Fill out imported functions
Ghidra already comes with a great set of function defitions. It covers much of the WIN32 API for different Versions of Visual Studio. You can find the official set at ghidra-data on github. Functions that are missing but imported, you can easily add these to your project. A great reference is to use the WINE source code which offers them in convenient and readable header files.
Let’s examine this by taking a look at DirectDrawCreate. When importing a binary referencing this, Ghidra does not know about the calling conventions and parameters, so you can see the name but nothing else
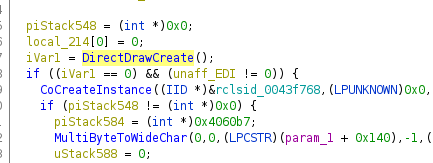
In the next step go ahead an fill out the function definition. This one was taken from wine’s ddraw.h.

You can finally see which parameters get passed to a function as well as the appropriate return code. Please note that you might need structure and type defintions. During working on this example I’ve created a library with the necessary types for DirectDraw, Direct3D and Direct3D9. You can find my type definitions on github.com/egore/ghidra-data.

Typing GetProcAddress and LoadLibrary
On Windows you can easily reference functions from a third party DLL by using LoadLibrary and GetProcAddress. In the example below you can see the loading and immediate use of this functionality. Before defining an appropriate type for the global DAT_XXXXXXXX fields, the code is hardly readable:

Only renaming the fields already alows better recognition. Combined with typing the to the Ghidra provided function definitions (e.g. “GetActiveWindow*” for GetActiveWindow), it make the code easily readable. One can quickly glance that this will invoke MessageBoxA from user32.dll on the active window or the last active popup.

Anyone familiar with the Magic added by the CRT might be able to recognize this function: it is the error path when something horribly went wrong to display an error before the program exits.
C++
Compiled C++ brings its own share of complexity, especially in understanding what is happening in regards of dynamic_cast and virtual methods. First of all in many cases the Ghidra-Cpp-Class-Analyzer does an incredibly good job at identifying Class and their virtual function tables. I will recommend a few patterns below to identify and add classes that were missed or only recreated incompletly by the plugin.
operator_new
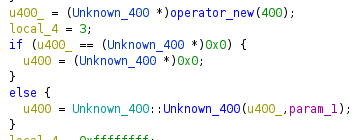
In nost cases you can look for a method named operator_new. Behind the scenes it is just a wrapper around malloc (or __nh_malloc and HeapAlloc due to the CRT magic), but it is recognized by Ghidra most of the time. In case it is not (e.g. when reverse engineering binaries from the last millenium) you can identify it yourself pretty easily. Once you found it, you will see it in a very common usage:

In the example you will see a memory allocation of 400 bytes. if this allocation was performed successful, it will immediately be passed to a function, which very likely is the constructor. As we don’t know the purpose of this class yet, I named it “Unknown_400” to indicate that it is unknown to me but has 400 bytes. I also renamed the method to look like a constructor.
Virtual function tables (vtables, vftables, _vfptr)
When looking further at the constructor you will see a common pattern:
- super class constructors are called (or inlined, which is really common)
- the virtual function table is set up
- the member fields are initialized
In our Unknown_400 example we can see exactly what was described above.
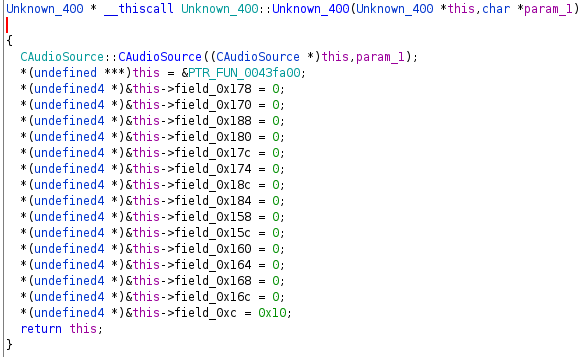
This gives away that PTR_FUN_0043fa00 is likely a function table, and indeed
it is: a list of functions from which the first one got a label by Ghidra (i.e.
it is referenced by address somewhere). I usually go ahead and mock the vtable
by a list of pointers which works really nice in Ghidras decompiler as it keeps
the display of the return value as well as the arguments (do not define the list
entries as undefined4 or even int, which prevents the decompiler from
proper diplay).
Using “Auto Fill in Class Structure” we end up with a pretty decent looking constructor:
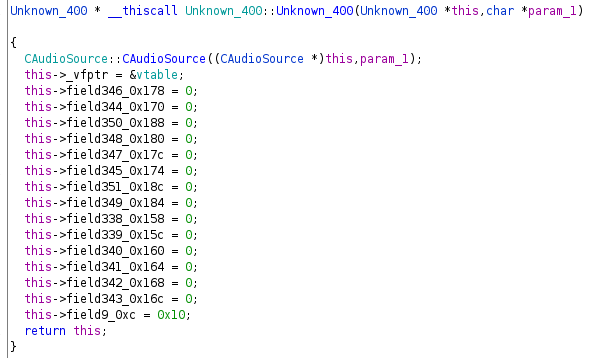
Using the referenced to the vtable you can also find the destructor, which likely is also the first member pointer of the vtable. The destructor will do what the constructor did in reverse:
- set up the vtable to our own (in case it was overwritten by a child class)
- clean up the fields
- call the super class destructor (or have it inlined)
IUnknown
The IUnknown interface is used in the WIN32 API to pass along objects of a
size unknown to the caller, but with a known API. It differs from a normal
C++ class definition in that way you don’t know anything about member
variables.
If we look at the example of IDirectDrawColorControl from WINE
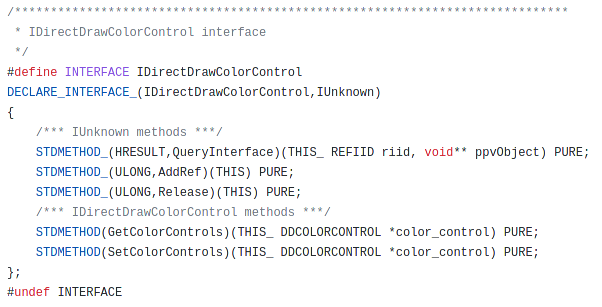
It inherites from IUnknown and brings alone two methods. To represent this in Ghidra I will do what is shown below. First of all I create the necessary interface IDirectDrawColorControl plus an empty IDirectDrawColorControlVtbl being referenced by the interface.

To fill the vtable I will create the according function defintions (if time permits, otherwise these will just be pointers) and add them. The first three methods are inherited from IUnknown to I simply reuse the IUnknownVtl provided by Ghidra.
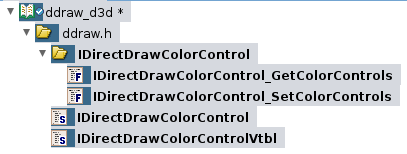

Please note that usually adding the function definitions takes a lot of time, as you will have to create additional structures, typedefs and interfaces as well. But for complex interfaces (e.g. IDirectDrawSurface vs. IDirectDrawSurface4 vs. IDirectDrawSurface7) it quickly becomes relevant.
Magic added by the CRT
When using Visual Studio it will take care to prevent you from programming errors by adding some magic to the C runtime (CRT). This magic is not visible in the code, but behind the scenes. Where it bit me the most was for file related APIs. I was used to think how fopen works. When looking at the disassembly of the file related APIs you will notice something different: the FILE passed to methods is not a simple file, but a __crt_stdio_stream_data. What this basically does is combining a the FILE handle with a CRITICAL_SECTION used for locking any file access. This is indeed a good idea with an acceptable performance overhead (I/O is more likely the slow part of a call, not some locking) and it easily prevents programming errors. Unfortunately you have to identify the inner workings of the methods first to identify these, as Ghidra 10.1 was not able to detect these and was also unaware of __crt_stdio_stream_data.
As mentioned above some other methods also behave differently. When looking at malloc for example, it uses __nh_malloc to allocate memory using the Windows HeapAlloc APIs. While this is totally fine, it also brings its own share of complexity to a binary.
Exception handling
Especially in C++ you have to be aware of magic behind the scenes for exception handling. On Windows you will see EH or SEH (structured exception handling) in place, which adds a bit of clutter to methods.
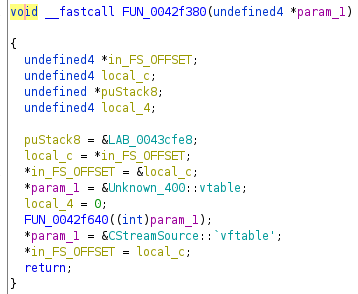
Whenever I see in_FS_OFFSET, local_c puStack8 and local_4 in a decompiled method, I just ignore it as my focus is on the “happy path”, i.e. whenever the program does not throw an exception. As far as I am aware there is no coverage on the topic and the Ghidra decompiler does not yet add the syntactic sugar to make this readable (see Ghidra issue tracker 2477).
/GS Buffer Security Check
When a program is compiled using the compiler option /GS, you will find a bit of magic on each and every method which utilizes the stack (i.e. almost everything). You can spot this by looking into ___security_init_cookie, which sets up a global variable I usually call SECURITY_COOKIE. In the methods you will see an added prolog:
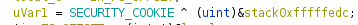
And epilog:
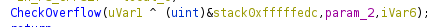
Magic added by thirdparty DLLs
It sometimes happens that some code parts behave way different than others. This usually boils down to them being authored by someone else, using different standards and patterns. It is common to have several methods logging using OutputDebugString, while others do so using fprintf.
In very obscure code paths you will stumble upon behaviour hard to explain. One example you should always keep in mind is that C and C++ is preprocessor based. You can do really funky things like writing your own allocator and do the following
#undef new
#define new MY_WAY_BETTER_ALLOCATOR
Depending on the scope this will not only alter your own code, but also apply to others.











